HTTP2中,多路复用的原理是什么?
参考答案:
HTTP/2是一个二进制协议,其基于“帧”的结构设计,改进了很多HTTP/1.1痛点问题。
什么是多路复用?
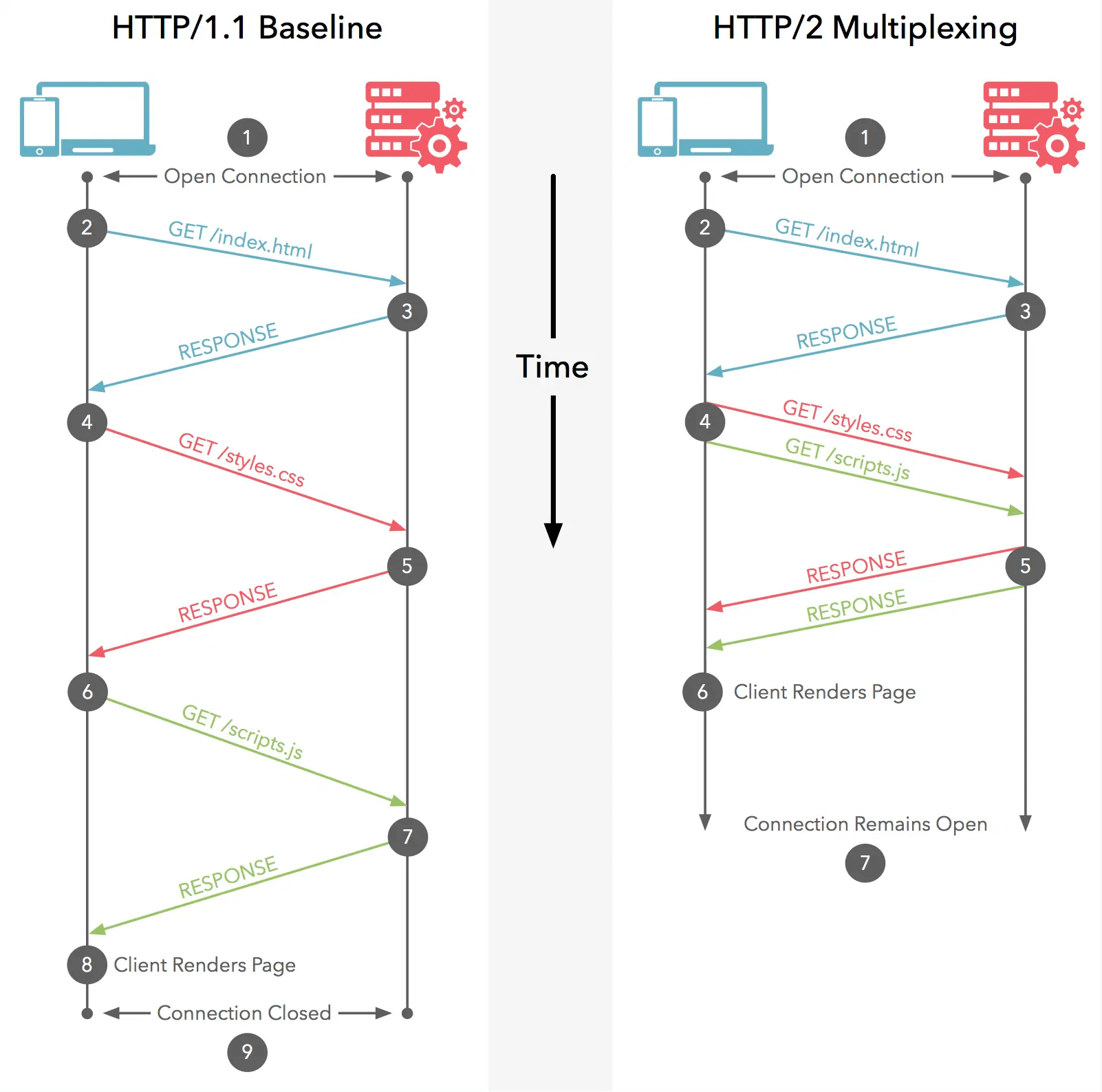
HTTP/1.1协议的请求-响应模型大家都是熟悉的,我们用“HTTP消息”来表示一个请求-响应的过程,那么HTTP/1.1中的消息是“管道串形化”的:只有等一个消息完成之后,才能进行下一条消息;而HTTP/2中多个消息交织在了一起,这无疑提高了“通信”的效率。这就是多路复用:在一个HTTP的连接上,多路“HTTP消息”同时工作。
为什么 HTTP/1.1 不能实现“多路复用”?
简单回答就是:HTTP/2 是基于二进制“帧”的协议,HTTP/1.1是基于“文本分割”解析的协议。
HTTP/1.1 发送请求消息的文本格式:以换行符分割每一条 key:value 的内容,解析这种数据用不着什么高科技,相反的,解析这种数据往往速度慢且容易出错。“服务端”需要不断的读入字节,直到遇到分隔符(这里指换行符,代码中可能使用/n或者/r/n表示),这种解析方式是可行的,并且 HTTP/1.1 已经被广泛使用了二十多年,这事已经做过无数次了,问题一直都是存在的:
- 一次只能处理一个请求或响应,因为这种以分隔符分割消息的数据,在完成之前不能停止解析。
- 解析这种数据无法预知需要多少内存,这会带给“服务端”很大的压力,因为它不知道要把一行要解析的内容读到多大的“缓冲区”中,在保证解析效率和速度的前提下:内存该如何分配?
HTTP/2帧结构设计和多路复用实现
前边提到:HTTP/2设计是基于“二进制帧”进行设计的,这种设计无疑是一种“高超的艺术”,因为它实现了一个目的:一切可预知,一切可控。
帧是一个数据单元,实现了对消息的封装。下面是HTTP/2的帧结构:
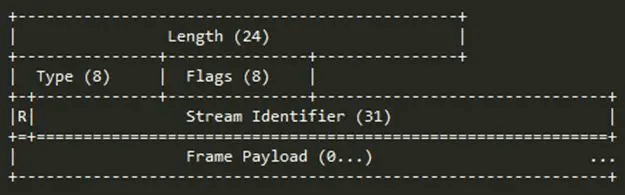
帧的字节中保存了不同的信息,前9个字节对于每个帧都是一致的,“服务器”解析HTTP/2的数据帧时只需要解析这些字节,就能准确的知道整个帧期望多少字节数来进行处理信息。
如果使用HTTP/1.1的话,你需要发送完上一个请求,才能发送下一个;由于HTTP/2是分帧的,请求和响应可以交错甚至可以复用。 为了能够发送不同的“数据信息”,通过帧数据传递不同的内容,HTTP/2中定义了10种不同类型的帧。
有了以上对HTTP/2帧的了解,我们就可以解释多路复用是怎样实现的了,不过在这之前我们先来了解“流”的概念:HTTP/2连接上独立的、双向的帧序列交换。流ID(帧首部的6-9字节)用来标识帧所属的流
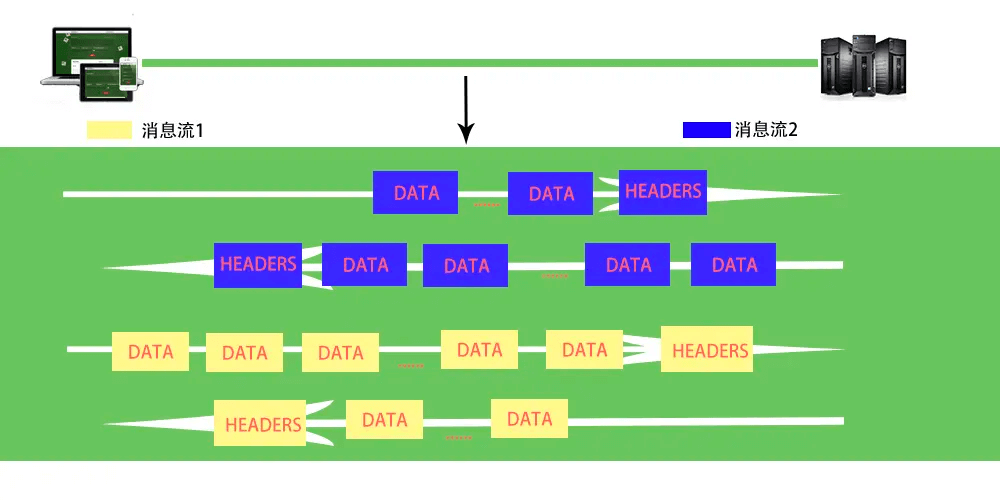
下面两张图分别表示了HTTP/2协议上POST请求数据流“复用”的过程,很容易看的明白:
本答案由“前端面试题宝典”收集整理,PC端访问请前往: https://fe.ecool.fun/
题目要点:
HTTP/2是一个二进制协议,通过“帧”的结构设计改进了HTTP/1.1的许多问题。多路复用是HTTP/2的核心特性之一,它允许在一个HTTP连接上同时处理多个HTTP消息,从而提高了通信效率。
在HTTP/1.1中,请求和响应是按照顺序处理的,一次只能处理一个请求或响应。这是因为HTTP/1.1是基于文本分割解析的协议,需要等待一个消息完成才能处理下一个。这种处理方式限制了效率,因为服务端需要不断读取字节直到遇到分隔符,而且无法预知需要多少内存来处理这些数据。
HTTP/2使用二进制帧来封装消息,每个帧都有固定的长度,使得服务器可以预知每个帧的大小,从而更有效地处理数据。HTTP/2定义了10种不同类型的帧,包括设置帧、数据帧、优先帧等,用于在连接上传输不同类型的信息。
在HTTP/2中,每个连接上的独立、双向帧序列称为“流”。流ID用于标识帧所属的流,这样客户端和服务端就可以同时发送和接收多个流,实现多路复用。
总的来说,HTTP/2的多路复用特性通过二进制帧和流的概念,使得客户端和服务端可以在一个连接上同时处理多个请求和响应,从而提高了网络性能和效率。